Content from Motivation
Last updated on 2024-07-25 | Edit this page
Overview
Questions
- Why version control?
- Why Git?
Objectives
- Understand the benefits of an automated version control system.
- Understand the basics of how automated version control systems work.
Why do we need version control?
We’ll start by exploring how version control can be used to keep track of what one person did and when. Even if you aren’t collaborating with other people, automated version control is much better than this situation:

We’ve all been in this situation before: it seems unnecessary to have multiple nearly-identical versions of the same document. Some word processors let us deal with this a little better, such as Microsoft Word’s Track Changes, Google Docs’ version history, or LibreOffice’s Recording and Displaying Changes.
Version control systems start with a base version of the document and then record changes you make each step of the way. You can think of it as a recording of your progress: you can rewind to start at the base document and play back each change you made, eventually arriving at your more recent version.

Once you think of changes as separate from the document itself, you can then think about “playing back” different sets of changes on the base document, ultimately resulting in different versions of that document. For example, two users can make independent sets of changes on the same document.

Unless multiple users make changes to the same section of the document - a conflict - you can incorporate two sets of changes into the same base document.

A version control system is a tool that keeps track of these changes for us, effectively creating different versions of our files. It allows us to decide which changes will be made to the next version (each record of these changes is called a commit), and keeps useful metadata about them. The complete history of commits for a particular project and their metadata make up a repository. Repositories can be kept in sync across different computers, facilitating collaboration among different people.
Have you ever said or heard…
- “I will just finish my work and then you can start with your changes.”.
- “Can you please send me the latest version?”.
- “Where is the latest version?”.
- “Which version are you using?”.
- “Which version have the authors used in the paper I am trying to reproduce?”.
Then version control is for you
Discussion : Paper Writing
Imagine you drafted an excellent paragraph for a paper you are writing, but later ruin it. How would you retrieve the excellent version of your conclusion? Is it even possible?
Imagine you have 5 co-authors. How would you manage the changes and comments they make to your paper? If you use LibreOffice Writer or Microsoft Word, what happens if you accept changes made using the
Track Changesoption? Do you have a history of those changes?
What is version control?
There are lots of different tools that implement version control (generally referred to as Version Control Systems, VCS). They all have common features, including:
- A system which records snapshots of a project
- Implementation of branching:
- you can work on several feature branches and switch between them
- different people can work on the same code/project in parallel without interfering
- you can experiment with an idea and discard it if it turns out to be a bad idea
- Implementation of merging:
- tool to merge different versions of a file
Code becomes a disaster without version control
Roll-back functionality
- Mistakes happen - without recorded snapshots you cannot easily undo mistakes and go back to a working version.
Branching
- Often you want to experiment with an idea, or work on different approaches in one file - without branching this can be messy and confusing.
- You could simulate branching by copying an entire project to multiple places but this would be messy and confusing.
We will use Git as our VCS to record snapshots of our work - why Git?
- Easy to set up - use even by yourself with no server needed.
- Very popular: if contributing to somebody else’s code, chances are it’s tracked with Git.
- Distributed: good backup, no single point of failure, you can track and clean-up changes offline, simplifies collaboration model for open-source projects.
- Important platforms such as GitHub, GitLab, and Bitbucket build on top of Git.
- Sharing software and data is getting popular and required in research context and sites like GitHub are a popular platform for sharing software.
Key Points
- Version control is like an unlimited ‘undo’.
- Version control also allows many people to work in parallel.
Content from In-browser session
Last updated on 2024-07-29 | Edit this page
Overview
Questions
- Where are we heading?
Objectives
- See an existing repository in action.
- Browse the history.
- See the big picture first before we dive into details.
In-browser session
- We will explore and visualize an existing Git repository on BitBucket.
- The goal of this episode is not to teach BitBucket, but rather to get a glimpse of the wider picture before going into the details.
Why?
- Often our first contact with Git is an existing repository.
- It’s good to see the social aspect to know what our end goal is.
- Don’t worry about the details of the steps here, just investigate what we can learn about an existing repository.
Bitbucket demo
We’ll start with a very simple existing repository that contains a brief history from a couple of different people.
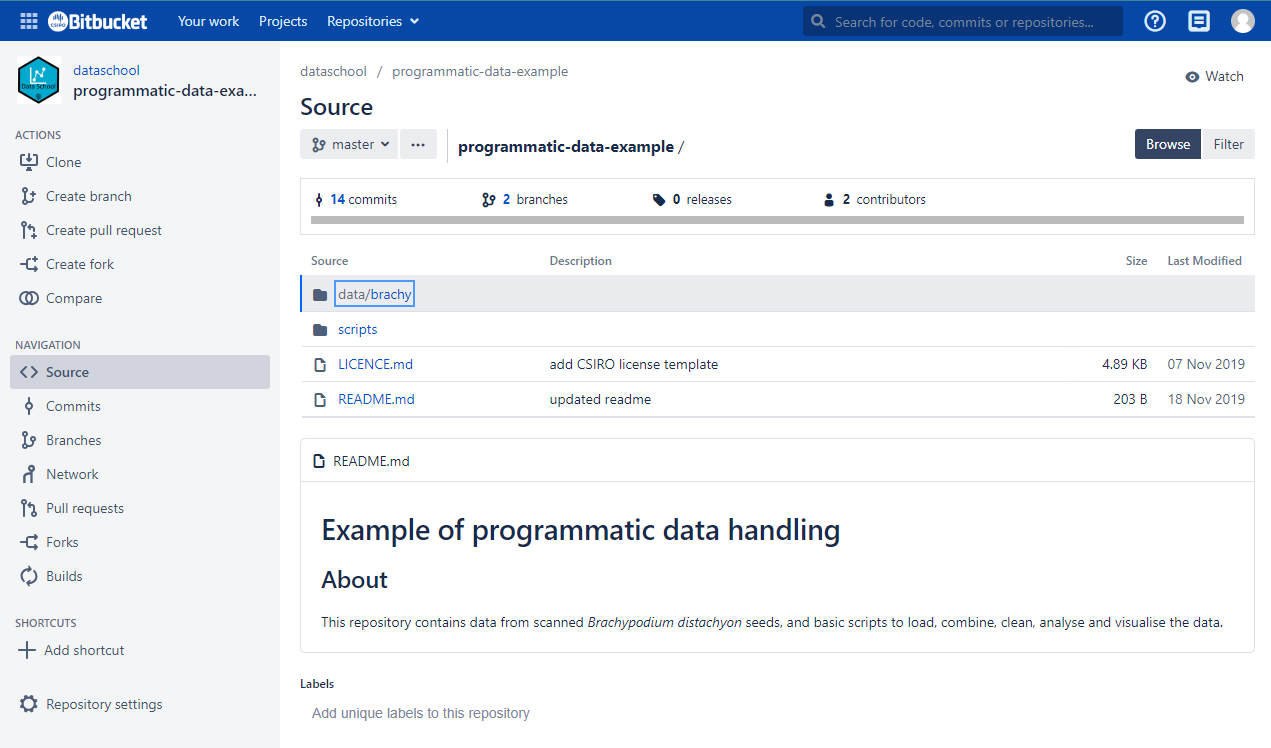
- History
- Explore the repository.
- Explore the history and commits.
- Note that there are branches.
- Reproducibility
- Explore the ‘blame’ feature.
- Collaboration
- You can refer to code portions (so much simpler to send a link rather than describe which file to open and where to scroll to).
- Note the contributors.
- As a file source
- We can create a local copy of all files in a repository through a clone
git clone https://bitbucket.csiro.au/scm/dat/programmatic-data-example.git
These features are all based on the core underlying Git system, that works independently of Bitbucket and is shared by other sites such as GitHub and GitLab.
GitHub demo
These
lessons are themselves tracked through Git, but stored on GitHub
(making use of the automatic webpage generation feature GitHub
Pages).
Note that GitHub looks very different to BitBucket, but all of the same
information and features may be found, with a click around.
This version of Git Intro lessons is a modified “fork” of an older version, which was itself a “fork” of other older versions. A fork is a full copy of a repository into a new repository, which retains full history but allows it to branch in its own separate direction, under separate control. We’ll discuss forks further later.
The bulk of these lessons are thanks to the Code Refinery and Software Carpentry Git lessons, also in their own Git repositories.
Key Points
- There are multiple online repositories for storing projects that all use the underlying Git framework
- Bitbucket is one such service, using Git to provide functionality to collaborate with other people
- We can browse the history of the contents of repositories and see who made which changes
- Other platforms like Github look different by employ the same fundamentals
Content from Configuring Git
Last updated on 2024-07-29 | Edit this page
Overview
Questions
- How do we configure git?
- What are our options for text editors?
Objectives
- Learn how to configure the most useful git options.
Configuring Git
All the configuration we enter here will be stored in a file
~/.gitconfig.
When we use Git on a new computer for the first time, we need to configure a few things. Below are a few examples of configurations we will set as we get started with Git:
- our name and email address,
- what our preferred text editor is,
- and that we want to use these settings globally (i.e. for every project).
Let’s work through it together in Git Bash.
First, the following commands will set your user name and email address:
BASH
$ git config --global user.name "Your Name"
$ git config --global user.email yourname@example.comThe name and contact email will be recorded together with the code
changes when we run git commit.
Private email
If you’re using GitHub, and if you’d like to keep your personal email address private, you can use a GitHub-provided no-reply email address as your commit email address. See here for further details.
Line Endings
As with other keys, when you hit Return on your keyboard, your computer encodes this input as a character. Different operating systems use different character(s) to represent the end of a line. (You may also hear these referred to as newlines or line breaks.) Because Git uses these characters to compare files, it may cause unexpected issues when editing a file on different machines. Though it is beyond the scope of this lesson, you can read more about this issue on this GitHub page.
You can change the way Git recognizes and encodes line endings using the
core.autocrlfcommand togit config. The following settings are recommended:On macOS and Linux:
And on Windows:
Setting a default text editor
When you work with Git, you often need to make small text files to describe a ‘snapshot’. When this is necessary, Git will open whatever default text editor you have set. This means it’s often useful to choose which text editor you prefer, and set it as the default. On your local machine, you can set it to be whatever you like, but if you’re working on a remote system, you will only have access to editors that are available there.
Below is a list of commands to set the default editor to a list of common tools. If you don’t have any of these available, you might want to install Sublime Text, which is a great option that you can download from https://www.sublimetext.com/3, or VS Code, which is also great and in addition is free.
| Editor | Configuration command |
|---|---|
| Atom | $ git config --global core.editor "atom --wait" |
| BBEdit (Mac, with command line tools) | $ git config --global core.editor "bbedit -w" |
| Emacs | $ git config --global core.editor "emacs" |
| Gedit (Linux) | $ git config --global core.editor "gedit --wait --new-window" |
| Kate (Linux) | $ git config --global core.editor "kate" |
| nano | $ git config --global core.editor "nano -w" |
| Notepad++ (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Notepad++ (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Scratch (Linux) | $ git config --global core.editor "scratch-text-editor" |
| Sublime Text (Mac) | $ git config --global core.editor "/Applications/Sublime\ Text.app/Contents/SharedSupport/bin/subl -n -w" |
| Sublime Text (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/sublime text 3/sublime_text.exe' -w" |
| Sublime Text (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/sublime text 3/sublime_text.exe' -w" |
| Vim | $ git config --global core.editor "vim" |
| VS Code | $ git config --global core.editor "code --wait" |
Optional: Git GUI
You might find it easier to know what is going on if you install a Graphical User Interface.
There are many options here. Depending on your installation of git
you might have a built-in basic GUI called gitk or
[QGit](https://github.com/tibirna/qgit#readme). This is
free. Alternatively you might try a commercial git GUI. Here are some
popular ones:
-
Sourcetree (macOS,
Windows)
- Sublime merge (macOS, Windows, Linux)
- Gitkraken (macOS, Windows, Linux)
- Fork (macOS, Windows)
Sourcetree is available for CSIRO staff within the Software Center.
None of these are needed for this introductory tutorial, but they can be helpful to build understanding.
Key Points
- git configuration is all stored in
~/.gitconfig - The config is specific to each computer you use.
Content from Our first repo
Last updated on 2024-07-29 | Edit this page
Overview
Questions
- What is a repository?
- How does Git operate?
- How do I make commits?
- How do I select what to commit?
Objectives
- Learn to create Git repositories and make commits.
- Get a grasp of the structure of a repository.
- Learn how to inspect the project history.
- Learn how to write useful commit log messages.
Tracking a guacamole recipe with Git
We will learn how to initialize a Git repository, how to track changes, and how to make delicious guacamole!
This example is inspired by Byron Smith, for original reference, see this thread. The motivation for taking a cooking recipe instead of a program is that everybody can relate to cooking but not everybody may be able to relate to a program written in e.g. Python or another language.
Let’s start.
Make a new directory for this lesson. We’ll store the Git repositories we make inside this directory.
One of the basic principles of Git is that it is easy to create repositories:
From inside your new directory:
That’s it! We have now created an empty Git repository.
If we use ls to show the directory’s contents, it
appears that nothing has changed:
But if we add the -a flag to show everything, we can see
that Git has created a hidden directory within recipe
called .git:
OUTPUT
. .. .git Git uses this special sub-directory to store all the information about the project, including all files and sub-directories located within the project’s directory. If we ever delete the .git sub-directory, we will lose the project’s history.
We will use git status a lot to check out to see what is
going on with the repository:
OUTPUT
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)We will make sense of this information during this lesson.
So what exactly is a Git repository?
- Remember Git is a version control system: it records snapshots and tracks the content of a folder as it changes over time.
- Every time we commit a snapshot, Git records a
snapshot of the entire project, saves it, and assigns
it a version.
- It does this efficiently, by recording just the changes from one snapshot to the next, called the diff.
- These snapshots are kept inside the
.gitsub-folder. - If we remove
.git, we remove the repository and history (but keep the working directory!). -
.gituses relative paths - you can move the whole thing somewhere else and it will still work - Git doesn’t do anything unless you ask it to (it does not record anything automatically).
Recording a snapshot with Git
- Git takes snapshots only if we request it.
- We will record changes always in two steps (we will later explain why this is a recommended practice):
- We first focus (
git add, we “stage” the change), then shoot (git commit):

Discussion
What do you think will be the outcome if you stage a file and then edit it and stage it again, do this several times and at the end perform a commit? (think of focusing several scenes and pressing the shoot button only at the end)
So that’s the concept - let’s do it for real.
Let’s create two files.
One file is called instructions.txt and contains:
* chop avocados
* chop onion
* squeeze lime
* add salt
* and mix wellThe second file is called ingredients.txt and
contains:
* 2 avocados
* 1 lime
* 2 tsp saltAs mentioned above, in Git you can always check the status of files
in your repository using git status. It is always a safe
command to run and in general a good idea to do when you are trying to
figure out what to do next:
OUTPUT
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
ingredients.txt
instructions.txt
nothing added to commit but untracked files present (use "git add" to track)The two files are untracked in the repository (directory). Going back
to the photography analogy, you want to add the
files (focus the camera) to the list of files tracked by Git.
Git does not track any files automatically and you need make a conscious
decision to add a file. Let’s do what Git hints at and add the
files:
OUTPUT
On branch main
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: ingredients.txt
new file: instructions.txtNow this change is staged and ready to be committed (the camera is focused and we’re ready to take the snapshot).
Let’s now commit the change to the repository:
OUTPUT
[main (root-commit) aa243ea] adding ingredients and instructions
2 files changed, 8 insertions(+)
create mode 100644 ingredients.txt
create mode 100644 instructions.txtRight after we query the status to get this useful command into our muscle memory:
Looking at the history
Now try git log to see the information that git has
stored about your snapshot:
OUTPUT
commit 787611f02dd6fc862c87359b804859caa5d2fdbd
Author: Alex Whan <alexwhan@gmail.com>
Date: Wed Mar 13 17:07:44 2019 +1100
adding ingredients and instructions- We can browse the development and access each state that we have committed.
- The long hashes uniquely label a state of the code.
- They are not just integers counting 1, 2, 3, 4, … (why?).
- We will use them when comparing versions and when going back in time.
-
git log --onelineonly shows the first 7 characters of the commit hash and is good to get an overview. - If the first characters of the hash are unique it is not necessary to type the entire hash.
-
git log --statis nice to show which files have been modified.
OUTPUT
diff --git a/ingredients.txt b/ingredients.txt
index 2607525..ec0abc6 100644
--- a/ingredients.txt
+++ b/ingredients.txt
@@ -1,3 +1,4 @@
* 2 avocados
* 1 lime
* 2 tsp salt
+* 1/2 onion
diff --git a/instructions.txt b/instructions.txt
index 6a8b2af..f7dd63a 100644
--- a/instructions.txt
+++ b/instructions.txt
@@ -3,3 +3,4 @@
* squeeze lime
* add salt
* and mix well
+* enjoy!- The output shows which files are being compared - the “before” and “after” versions of the same file.
- The new lines added are prefixed with a
+sign to show that they are new.
Challenge 2
Stage and commit each change separately. For the second commit, don’t
use the -m flag.
What are the steps to run?
What happens if you don’t use -m?
A possible example:
BASH
$ git add ingredients.txt
$ git commit -m "add half an onion"
$ git add instructions.txt
$ git commit When you leave out the -m flag, Git should open an
editor where you can edit your commit message. This message will be
associated and stored with the changes you made. This message is your
chance to explain what you’ve done and convince others (and your future
self) that the changes you made were justified.
Using a text editor (instead of -m) can be useful
because you can include much longer commit messages.
Writing useful commit messages
Using git log --oneline we understand that the first
line of the commit message is very important.
Good example:
increase threshold alpha to 2.0
the motivation for this change is
to enable ...
...Convention: one line summarizing the commit, then one empty line, then paragraph(s) with more details in free form, if necessary.
- Bad commit messages: “fix”, “oops”, “save work”, “foobar”, “toto”, “qppjdfjd”, ““.
- For your amusement: http://whatthecommit.com
- Write commit messages in English that will be understood 15 years from now by someone else than you.
Ignoring files and paths with .gitignore
Some files should not be tracked in a Git repository. This includes files that are: - specific to a particular computer - contain sensitive information - large, binary files - compiled files
Discussion
What could be the problems raised by committing the above files to a repo?
For this we use .gitignore files. Example:
# ignore R binary files
*.RData
# ignore .exe files
*.exeChallenge 3
Make a new file called my-personal-notes.txt. Add some
content to the file that describes your feelings about Git so far…
Since you might not want these comments seen by collaborators, make sure it is ignored by git
By adding the path my-personal-notes.txt to the
.gitignore file, your personal thoughts about Git won’t be
added to any snapshots.
You can have .gitignore files in lower level directories
and they affect the paths relatively.
.gitignore should be part of the repository (why?).
GUI tools
It is also possible to work from within a Git graphical user interface (GUI):
Summary
Now we know how to save snapshots (commits):
And this is what we do as we program.
Every state is then saved and later we will learn how to go back to these “checkpoints” and how to undo things.
BASH
$ git init # initialize new repository
$ git add # add files or stage file(s)
$ git commit # commit staged file(s)
$ git status # see what is going on
$ git log # see history
$ git diff # show unstaged/uncommitted modifications
$ git show # show the change for a specific commit
$ git mv # move tracked files
$ git rm # remove tracked filesKey Points
- Initializing a Git repository is simple:
git init - Commits should be used to tell a story.
- Git uses the .git folder to store the snapshots.
Content from Undoing things
Last updated on 2024-07-29 | Edit this page
Overview
Questions
- How can I undo things?
Objectives
- Learn to undo changes safely
- See when changes are permanently deleted and when they can be retrieved
Undoing things
The whole point of version control is that you can be see and retrieve previous snapshots of your work.
With Git, if you have committed (made a snapshot) of a file, you can get it back, even if it gets deleted or modified in the future.
Some commands will modify the hitory of a Git repository. This is generally a very bad idea, and you should only do it if you’re really confident you know what you’re doing.
If changes are uncommitted, they are not safe, and if they are deleted, they are gone.
Reverting commits
- Imagine we made a few commits.
- We realize that the latest commit was a mistake and we wish to undo it:
OUTPUT
f960dd3 (HEAD -> main) not sure this is a good idea
40fbb90 draft a readme
dd4472c we should not forget to enjoy
2bb9bb4 add half an onion
2d79e7e adding ingredients and instructionsA safe way to undo the commit is to revert the commit with
git revert:
This creates a new commit that does the opposite of the reverted commit. The old commit remains in the history:
OUTPUT
d62ad3e (HEAD -> main) Revert "not sure this is a good idea"
f960dd3 not sure this is a good idea
40fbb90 draft a readme
dd4472c we should not forget to enjoy
2bb9bb4 add half an onion
2d79e7e adding ingredients and instructionsChallenge 1
Make a new commit in your guacamole repo (it can be whatever you like)
Inspect the history, and revert the commit.
Undo unstaged/uncommitted changes
git restore is used to restore a file, or all files,
back to a previously commited state.
Note: Older versions of git used
git checkout <file> instead of
restore.
DANGER!!
This command permanently deletes any changes that haven’t been staged/committed!
Modify before staging
- Make a silly change to repo, do not stage it or commit it.
- Inspect the change with
git statusandgit diff. - Now undo the change with
git restore <file>. - Verify that the change is gone with
git statusandgit diff.
Modify after staging
- Make a reasonable change to a project, stage it.
- Make a silly change after you have staged the reasonable change.
- Inspect the situation with
git status,git diff,git diff --staged, andgit diff HEAD. - Now undo the silly change with
git restore <file>. - Inspect the new situation with
git status,git diff,git diff --staged, andgit diff HEAD.
Challenge 2
How much do you trust Git…?
Delete one (or more) of your committed files using any method you like.
Can you get it/them back?
As long as a file was committed, you can get it back with
git restore <file>, but Git isn’t magic - you won’t
have any changes that weren’t committed.
Recovering a previous versions
Because git stores the complete history of whatever snapshots you have recorded, you can step back to anyone of them at different levels of detail, from the complete working directory, to single files, even to single changes within files.
To get back to a previous state for the whole working directory, you
can use git restore [-s <commit>] .. Jumping back to
a previous commit can be useful for having a look at files, but you may
get a warning about a detached HEAD (more discussion later).
Recovering previous versions of single files
Often it’s useful to be able to access a previous version of a
particular file. When the restore command is given a file
path (along with a reference to a commit with “-s” or “–source=”) it
will update that path to the previous state.
Let’s see that with our recipe. If we wanted to get
ingredients.txt back to its state before the addition of
the onion, we could run
OUTPUT
Updated 1 path from 2d79e7eIf you run git status you’ll see that the changes to the
file ingredients.txt, bringing it back to the previous
state, are already staged and ready to be committed.
Key Points
- Git history can be reverted without modifying it
- Once changes are committed they are safe
- Changes that are not committed can be deleted
Content from Branching and merging
Last updated on 2024-07-29 | Edit this page
Overview
Questions
- How can I or my team work on multiple features in parallel?
- How to combine the changes of parallel tracks of work?
- How can I permanently reference a point in history, like a software version?
Objectives
- Be able to create and merge branches.
- Know the difference between a branch and a tag.
Motivation for branches
In the previous section we tracked a guacamole recipe with Git.
Up until now our repository had only one branch with one commit coming after the other:

- Commits are depicted here as little boxes with abbreviated hashes.
- Here the branch
mainpoints to a commit. - “HEAD” is the current position (remember the recording head of tape recorders?).
- When we talk about branches, we often mean all parent commits, not only the commit pointed to.
Now we want to do this:
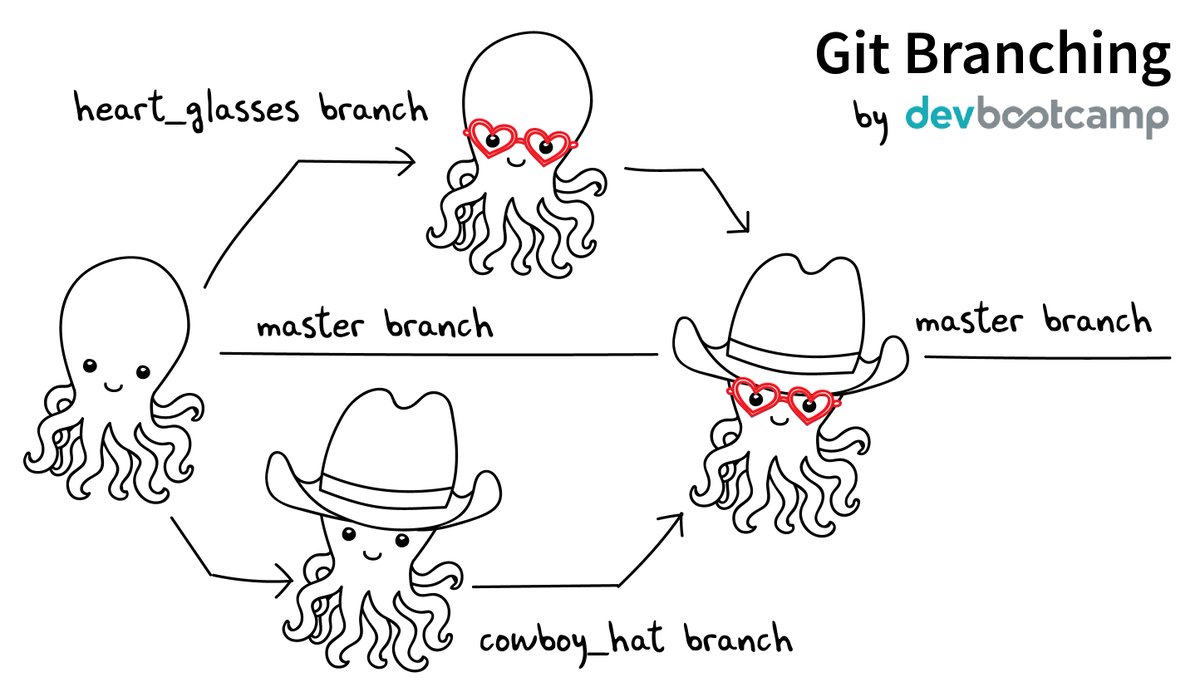
(Source: https://twitter.com/jay_gee/status/703360688618536960)
Software development is often not linear:
- We typically need at least one version of the code to “work” (to compile, to give expected results, …).
- At the same time we work on new features, often several features concurrently. Often they are unfinished.
- We need to be able to separate different lines of work really well.
The strength of version control is that it permits the researcher to isolate different tracks of work, which can later be merged to create a composite version that contains all changes:

- We see branching points and merging points.
- Main line development is often called
main(ormasterin older conventions). - Other than this convention there is nothing special about
main, it is just a branch. - Commits form a directed acyclic graph (we have left out the arrows to avoid confusion about the time arrow).
A group of commits that create a single narrative are called a branch. There are different branching strategies, but it is useful to think that a branch tells the story of a feature, e.g. “fast sequence extraction” or “Python interface” or “fixing bug in matrix inversion algorithm”.
Let us inspect the project history using the git graph
alias:
OUTPUT
* dd4472c (HEAD -> main) we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructions- We have three commits and only one development line (branch) and
this branch is called
main. - Commits are states characterized by a 40-character hash (checksum).
-
git graphprint abbreviations of these checksums. - Branches are pointers that point to a commit.
- Branch
mainpoints to commitdd4472c8093b7bbcdaa15e3066da6ca77fcabadd. -
HEADis another pointer, it points to where we are right now (currentlymain)
On which branch are we?
To see where we are (where HEAD points to) use
git branch:
OUTPUT
* main- This command shows where we are, it does not create a branch.
- There is only
mainand we are onmain(star represents theHEAD).
In the following we will learn how to create branches, how to switch between them, how to merge branches, and how to remove them afterwards.
Creating and working with branches
Let’s create a branch called experiment where we add
cilantro to ingredients.txt.
BASH
$ git branch experiment main # create branch called "experiment" from main
# pointing to the present commit
$ git switch experiment # switch to branch "experiment"
$ git branch # list all local branches and show on which branch we are- Verify that you are on the
experimentbranch (note thatgit graphalso makes it clear what branch you are on:HEAD -> branchname):
OUTPUT
* experiment
main- Then add 2 tbsp cilantro on top of the
ingredients.txt:
* 2 tbsp cilantro
* 2 avocados
* 1 lime
* 2 tsp salt
* 1/2 onion- Stage this and commit it with the message “let us try with some cilantro”.
- Then reduce the amount of cilantro to 1 tbsp, stage and commit again with “maybe little bit less cilantro”.
We have created two new commits:
OUTPUT
* 6feb49d (HEAD -> experiment) maybe little bit less cilantro
* 7cf6d8c let us try with some cilantro
* dd4472c (main) we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructions- The branch
experimentis two commits ahead ofmain. - We commit our changes to this branch.
Interlude: The multipurpose “checkout” command
Older versions of git used git checkout for the actions
now handled by both restore and switch.
git checkout can still be found in a lot of documentation,
Git tools, and scripts. Depending on the context
git checkout can do very different actions:
- Switch to a branch:
- Bring the working tree to a specific state (commit):
- Set a file/path to a specific state (throws away all unstaged/uncommitted changes):
This is unfortunate from the user’s point of view but the way Git is
implemented it makes sense. Picture git checkout as an
operation that brings the working tree to a specific state. The state
can be a commit or a branch (pointing to a commit).
In Git 2.23 (2019-08-16) and later this is much nicer:
Exercise: create and commit to branches
In this exercise, you will create two new branches, make new commits to each branch. We will use this in the next section, to practice merging.
- Change to the branch
main. - Create another branch called
less-salt- Note! Makes sure you are on main branch when you create the
less-salt branch. A safer way would be to explicitly specify that you
want to branch from the main branch, e.g.:
git branch less-salt main
- Note! Makes sure you are on main branch when you create the
less-salt branch. A safer way would be to explicitly specify that you
want to branch from the main branch, e.g.:
- On this new branch reduce the amount of salt in your recipe.
- Commit your changes to this
less-saltbranch.
Use the same commands as we used above.
We now have three branches (in this case HEAD points to
less-salt):
OUTPUT
experiment
* less-salt
mainOUTPUT
* bf59be6 (HEAD -> less-salt) reduce amount of salt
| * 6feb49d (experiment) maybe little bit less cilantro
| * 7cf6d8c let us try with some cilantro
|/
* dd4472c (main) we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructionsHere is a graphical representation of what we have created:

- Now switch to
main. - Add and commit the following
README.mdtomain:
Now you should have this situation:
OUTPUT
* 40fbb90 (HEAD -> main) draft a readme
| * bf59be6 (less-salt) reduce amount of salt
|/
| * 6feb49d (experiment) maybe little bit less cilantro
| * 7cf6d8c let us try with some cilantro
|/
* dd4472c we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructions
Merging branches
It turned out that our experiment with cilantro was a good idea. Our
goal now is to merge experiment into main.
First we make sure we are on the branch we wish to merge into:
OUTPUT
experiment
less-salt
* mainThen we merge experiment into main:

We can verify the result in the terminal:
OUTPUT
* c43b24c (HEAD -> main) Merge branch 'experiment'
|\
| * 6feb49d (experiment) maybe little bit less cilantro
| * 7cf6d8c let us try with some cilantro
* | 40fbb90 draft a readme
|/
| * bf59be6 (less-salt) reduce amount of salt
|/
* dd4472c we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructionsWhat happens internally when you merge two branches is that Git creates a new commit, attempts to incorporate changes from both branches and records the state of all files in the new commit. While a regular commit has one parent, a merge commit has two (or more) parents.
To view the branches that are merged into the current branch we can use the command:
OUTPUT
experiment
* mainWe are also happy with the work on the less-salt branch.
Let us merge that one, too, into main:

We can verify the result in the terminal:
OUTPUT
* 4f00317 (HEAD -> main) Merge branch 'less-salt'
|\
| * bf59be6 (less-salt) reduce amount of salt
* | c43b24c Merge branch 'experiment'
|\ \
| * | 6feb49d (experiment) maybe little bit less cilantro
| * | 7cf6d8c let us try with some cilantro
| |/
* | 40fbb90 draft a readme
|/
* dd4472c we should not forget to enjoy
* 2bb9bb4 add half an onion
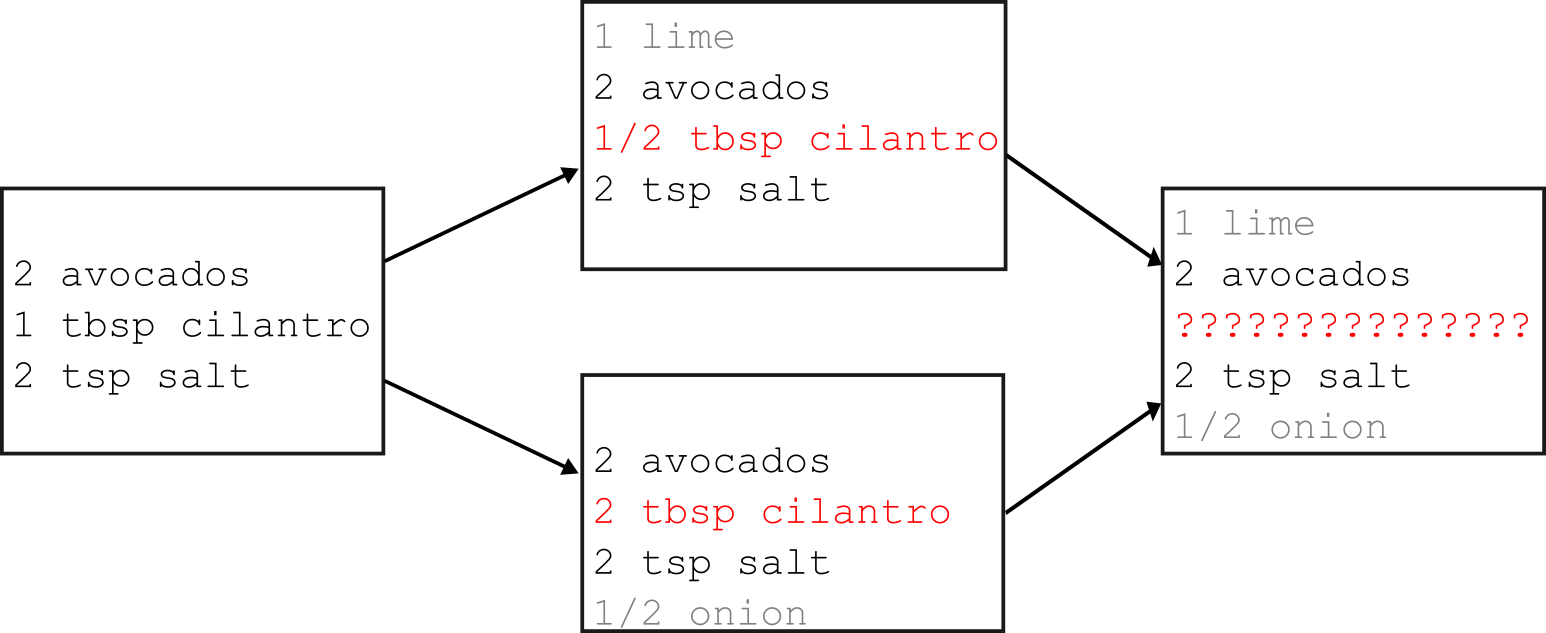
* 2d79e7e adding ingredients and instructionsObserve how Git nicely merged the changed amount of salt and the new ingredient in the same file without us merging it manually:
OUTPUT
* 1 tbsp cilantro
* 2 avocados
* 1 lime
* 1 tsp salt
* 1/2 onionIf the same file is changed in both branches, Git attempts to incorporate both changes into the merged file. If the changes overlap then the user has to manually settle merge conflicts (we will do that later).
Deleting branches safely
Both feature branches are merged:
OUTPUT
experiment
less-salt
* mainThis means we can delete the branches:
OUTPUT
Deleted branch experiment (was 6feb49d).
Deleted branch less-salt (was bf59be6).This is the result:

Compare in the terminal:
OUTPUT
* 4f00317 (HEAD -> main) Merge branch 'less-salt'
|\
| * bf59be6 reduce amount of salt
* | c43b24c Merge branch 'experiment'
|\ \
| * | 6feb49d maybe little bit less cilantro
| * | 7cf6d8c let us try with some cilantro
| |/
* | 40fbb90 draft a readme
|/
* dd4472c we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructionsAs you see only the pointers disappeared, not the commits.
Git will not let you delete a branch which has not been reintegrated
unless you insist using git branch -D. Even then your
commits will not be lost but you may have a hard time finding them as
there is no branch pointing to them.
Exercise: encounter a fast-forward merge
- Create a new branch from
mainand switch to it. - Create a couple of commits on the new branch (for instance edit
README.md):

- Now switch to
main. - Merge the new branch to
main. - Examine the result with
git graph. - Have you expected the result? Discuss what you see.
The following exercises are advanced, absolutely no problem to postpone them to a few months later. If you give them a go, keep in mind that you might run into conflicts, which we will learn to resolve in the next section.
(Optional) Exercise: Moving commits to another branch
Sometimes it happens that we commit to the wrong branch, e.g. to
main instead of a feature branch. This can easily be
fixed:
1. Make a couple of commits to main, then realize these
should have been on a new feature branch.
2. Create a new branch from main, and rewind
main back using
git reset --hard <hash>.
3. Inspect the situation with git graph. Problem
solved!
(Optional) Exercise: Rebasing
As an alternative to merging branches, one can also rebase
branches. Rebasing means that the new commits are replayed on
top of another branch (instead of creating an explicit merge
commit).
Note that rebasing changes history and should not be done on
public commits!
1. Create a new branch, and make a couple of commits on it.
2. Switch back to main, and make a couple of commits on
it.
3. Inspect the situation with git graph.
4. Now rebase the new branch on top of main by first
switching to the new branch, and then
git rebase main.
5. Inspect again the situation with git graph. Notice that
the commit hashes have changed - think about why!
(Optional) Exercise: Squashing commits
Sometimes you may want to squash incomplete commits,
particularly before merging or rebasing with another branch (typically
main) to get a cleaner history.
Note that squashing changes history and should not be done on
public commits!
1. Create two small but related commits on a new feature
branch, and inspect with git graph.
2. Do a soft reset with git reset --soft HEAD~2.
This rewinds the current branch by two commits, but keeps all changes
and stages them.
3. Inspect the situation with git graph,
git status and git diff --staged.
4. Commit again with a commit message describing the changes.
5. What do you think happens if you instead do
git reset --soft <hash>?
Summary
Let us pause for a moment and recapitulate what we have just learned:
BASH
$ git branch # see where we are
$ git branch <name> # create branch <name>
$ git switch <name> # switch to branch <name>
$ git merge <name> # merge branch <name> (to current branch)
$ git branch -d <name> # delete merged branch <name>
$ git branch -D <name> # delete unmerged branch <name>Since the following command combo is so frequent:
There is a shortcut for it:
Typical workflows
With this there are two typical workflows:
BASH
$ git switch -c new-feature # create branch, switch to it
$ git commit # work, work, work, ...
# test
# feature is ready
$ git switch main # switch to main
$ git merge new-feature # merge work to main
$ git branch -d new-feature # remove branchSometimes you have a wild idea which does not work. Or you want some throw-away branch for debugging:
BASH
$ git switch -c wild-idea
# work, work, work, ...
# realize it was a bad idea
$ git switch main
$ git branch -D wild-idea # it is gone, off to a new idea
# -D because we never merged backNo problem: we worked on a branch, branch is deleted,
main is clean.
Test your understanding
- Which of the following combos (one or more) creates a new branch and
makes a commit to it?
$ git branch new-branch $ git add file.txt $ git commit$ git add file.txt $ git branch new-branch $ git switch new-branch $ git commit$ git switch -c new-branch $ git add file.txt $ git commit$ git switch new-branch $ git add file.txt $ git commit - What is a detached
HEAD?
- What are orphaned commits?
- Both 2 and 3 would do the job. Note that in 2 we first stage the
file, and then create the branch and commit to it. In 1 we create the
branch but do not switch to it, while in 4 we don’t give the
-cflag togit switchto create the new branch. - When you check out a branch name, HEAD will point to the most recent
commit of that branch. You can however check out a particular
hash. This will bring your working directory back in time to that
commit, and your HEAD will be pointing to that commit but it will not be
attached to any branch. If you want to make commits in that state, you
should instead create a new branch:
git switch -c test-branch <hash>. - An orphaned commit is a commit that does not belong to any branch,
and therefore doesn’t have any parent commits. This could happen if you
make a commit in a detached HEAD state. Commits rarely vanish in Git,
and you could still find the orphaned commit using
git reflog.
Key Points
- A branch is a division unit of work, to be merged with other units of work.
- A tag is a pointer to a moment in the history of a project.
Content from Conflict resolution
Last updated on 2024-07-31 | Edit this page
Overview
Questions
- How can we resolve conflicts?
- How can we avoid conflicts?
Objectives
- Understand merge conflicts sufficiently well to be able to fix them.
Conflict resolution
In most cases a git merge runs smooth and automatic.
Then a merge commit appears (unless fast-forward) without you even
noticing.
Git is very good at resolving modifications when merging branches.
But sometimes the same line or portion of the code/text is modified on two branches and Git issues a conflict. Then you need to tell Git which version to keep (resolve it).
There are several ways to do that as we will see.
Please remember:
- Conflicts look scary, but are not that bad after a little bit of practice. Also they are luckily rare.
- Don’t be afraid of Git because of conflicts. You may not meet some conflicts using other systems because you simply can’t do the kinds of things you do in Git.
- You can take human measures to reduce them.
Type-along: create a conflict
We will make two branches, make two conflicting changes (both increase and decrease the amount of cilantro), and then try to merge them together. Git won’t decide which to take for you, so will present it to you for deciding. We do that and commit again to resolve the conflict.
- Create two branches from
main: one calledlike-cilantro, one calleddislike-cilantro:
$ git graphOUTPUT
* 4b3e3cc (HEAD -> main, like-cilantro, dislike-cilantro) Merge branch 'less-salt'
|\
| * bf59be6 reduce amount of salt
* | 80351a9 Merge branch 'experiment'
|\ \
| * | 6feb49d maybe little bit less cilantro
| * | 7cf6d8c let us try with some cilantro
| |/
* | 40fbb90 draft a readme
|/
* dd4472c we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructions- On the two branches make different modifications to the amount of the same ingredient:
$ git graphOUTPUT
* eee4b85 (dislike-cilantro) reduce cilantro to 0.5
| * 55d1ce2 (like-cilantro) please more cilantro
|/
* 4b3e3cc (HEAD -> main) Merge branch 'less-salt'
|\
| * bf59be6 reduce amount of salt
* | 80351a9 Merge branch 'experiment'
|\ \
| * | 6feb49d maybe little bit less cilantro
| * | 7cf6d8c let us try with some cilantro
| |/
* | 40fbb90 draft a readme
|/
* dd4472c we should not forget to enjoy
* 2bb9bb4 add half an onion
* 2d79e7e adding ingredients and instructionsOn the branch like-cilantro we have the following
change:
$ git diff main like-cilantroOUTPUT
diff --git a/ingredients.txt b/ingredients.txt
index a83af39..83f2f94 100644
--- a/ingredients.txt
+++ b/ingredients.txt
@@ -1,4 +1,4 @@
-* 1 tbsp cilantro
+* 2 tbsp cilantro
* 2 avocados
* 1 lime
* 1 tsp saltAnd on the branch dislike-cilantro we have the following
change:
$ git diff main dislike-cilantroOUTPUT
diff --git a/ingredients.txt b/ingredients.txt
index a83af39..2f60e23 100644
--- a/ingredients.txt
+++ b/ingredients.txt
@@ -1,4 +1,4 @@
-* 1 tbsp cilantro
+* 0.5 tbsp cilantro
* 2 avocados
* 1 lime
* 1 tsp saltWhat do you expect will happen when we try to merge these two branches into main?
The first merge will work:
OUTPUT
Updating 4b3e3cc..55d1ce2
Fast-forward
ingredients.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)But the second will fail:
OUTPUT
Auto-merging ingredients.txt
CONFLICT (content): Merge conflict in ingredients.txt
Automatic merge failed; fix conflicts and then commit the result.Without conflict Git would have automatically created a merge commit, but since there is a conflict, Git did not commit:
OUTPUT
On branch main
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: ingredients.txt
no changes added to commit (use "git add" and/or "git commit -a")Observe how Git gives us clear instructions on how to move forward.
Let us inspect the conflicting file:
OUTPUT
<<<<<<< HEAD
* 2 tbsp cilantro
=======
* 0.5 tbsp cilantro
>>>>>>> dislike-cilantro
* 2 avocados
* 1 lime
* 1 tsp salt
* 1/2 onionGit inserted resolution markers (the
<<<<<<<,
>>>>>>>, and
=======).
Try also git diff:
OUTPUT
diff --cc ingredients.txt
index 83f2f94,2f60e23..0000000
--- a/ingredients.txt
+++ b/ingredients.txt
@@@ -1,4 -1,4 +1,8 @@@
++<<<<<<< HEAD
+* 2 tbsp cilantro
++=======
+ * 0.5 tbsp cilantro
++>>>>>>> dislike-cilantro
* 2 avocados
* 1 lime
* 1 tsp saltgit diff now only shows the conflicting part, nothing
else.
We have to resolve the conflict. We will discuss 3 different ways to do this.
Manual resolution
<<<<<<< HEAD
* 2 tbsp cilantro
=======
* 0.5 tbsp cilantro
>>>>>>> dislike-cilantroWe have to edit the code/text between the resolution markers. You only have to care about what git shows you: Git stages all files without conflicts and leaves the files with conflicts unstaged.
Simple steps:
- Check status with
git statusandgit diff. - Decide what you keep (the one, the other, or both or something
else). Edit the file to do this.
- Remove the resolution markers, if not already done.
- The file(s) should now look exactly how you want them.
- Check status with
git statusandgit diff. - Tell Git that you have resolved the conflict with
git add ingredients.txt(if you use the Emacs editor with a certain plugin the editor may stage the change for you after you have removed the conflict markers). - Verify the result with
git status. - Finally commit the merge with just
git commit- everything is pre-filled.
Exercise: Create another conflict and resolve
In this exercise, we repeat almost exactly what we did above with a different ingredient.
- After you have merged
like-cilantroanddislike-cilantrocreate again two branches.
- Again modify some ingredient on both branches.
- Merge one, merge the other and observe a conflict, resolve the
conflict and commit the merge.
- What happens if you apply the same modification on both branches?
(Optional) Exercise: Conflicts and rebase
- Create two branches where you anticipate a conflict.
- Try to merge them and observe that indeed they conflict.
- Abort the merge.
- What do you expect will happen if you rebase one branch on top of the other? Do you anticipate a conflict? Try it out.
(Optional) Resolution using mergetool
- Again create a conflict (for instance disagree on the number of
avocados).
- Stop at this stage:
Auto-merging ingredients.txt
CONFLICT (content): Merge conflict in ingredients.txt
Automatic merge failed; fix conflicts and then commit the result.- Instead of resolving the conflict manually, use a visual tool
(requires installing one of the visual
diff tools):
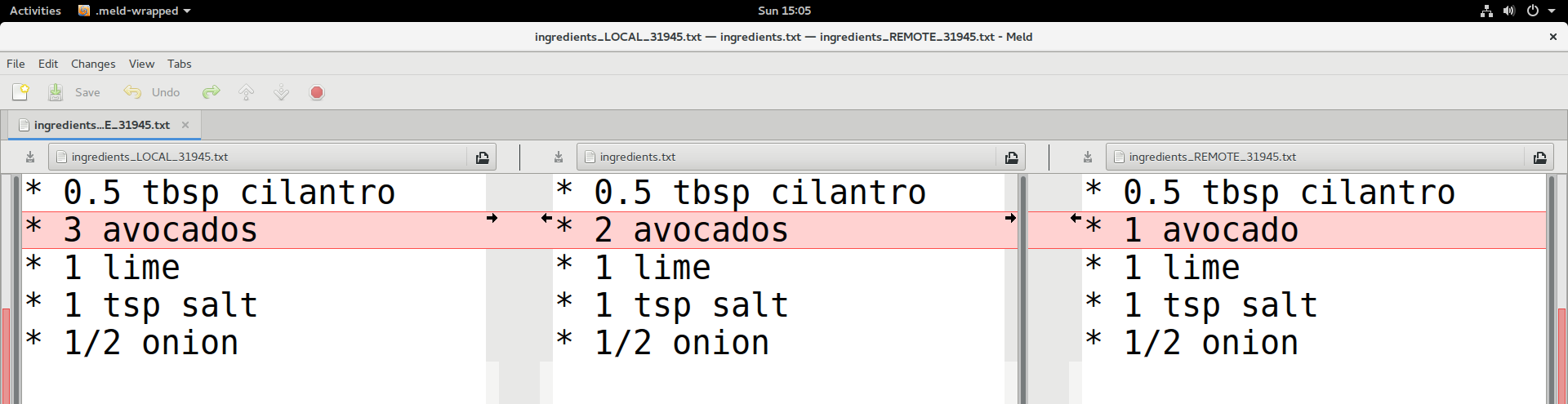
- Your current branch is left, the branch you merge is right, result
is in the middle.
- After you are done, close and commit,
git addis not needed when usinggit mergetool.
If you have not instructed Git to avoid creating backups when using mergetool, then to be on the safe side there will be additional temporary files created. To remove those you can do a git clean after the merging.
To view what will be removed:
To remove:
To configure Git to avoid creating backups at all:
Using “ours” or “theirs” strategy
- Sometimes you know that you want to keep “ours” version (version on
this branch) or “theirs” (version on the merged branch).
- Then you do not have to resolve conflicts manually.
- See merge strategies.
Example:
BASH
$ git merge -s recursive -Xours less-avocados
# merge and in doubt take the changes from current branchOr:
BASH
$ git merge -s recursive -Xtheirs less-avocados
# merge and in doubt take the changes from less-avocados branchAborting a conflicting merge
- Imagine it is Friday evening, you try to merge but have conflicts all over the place.
- You do not feel like resolving it now and want to undo the half-finished merge.
- Or it is a conflict that you cannot resolve and only your colleague knows which version is the one to keep.
What to do?
- There is no reason to delete the whole repository.
- You can undo the broken merge by resetting the repository to
HEAD(last committed state).
The repository looks then exactly as it was before the merge.
Avoiding conflicts
- Human measures
- Think and plan to which branch you will commit to.
- Few branches that contain many unrelated changes maximize risk of
conflicts.
- Use one branch for one task only.
- Think and plan to which branch you will commit to.
- Collaboration measures
- Conflicts can be avoided if you think and talk with your colleagues
before committing.
- Semantic conflicts that merge but don’t work: Importance of
talking!
- Conflicts can be avoided if you think and talk with your colleagues
before committing.
- Project layout measures
- Modifying global data often causes conflicts.
- Monolithic entangled code maximizes risk of conflicts.
- Modular programming minimizes risk of conflicts.
- Modifying global data often causes conflicts.
- Technical measures
-
Push early and often - this is one of the happy,
rare circumstances when everyone doing the selfish thing (pushing as
early as practical) results in best case for everyone!
- Pull/rebase often to keep up to date with upstream.
- Resolve conflicts early.
-
Push early and often - this is one of the happy,
rare circumstances when everyone doing the selfish thing (pushing as
early as practical) results in best case for everyone!
Discuss how Git handles conflicts compared to the Google Drive.
Key Points
- Conflicts usually appear because of not enough communication or not optimal branching strategy.
Content from Sharing repositories online
Last updated on 2024-07-31 | Edit this page
Overview
Questions
- How can I set up a public repository online?
- How can I clone a public repository to my computer?
Objectives
- To get a feeling for remote repositories.
- Learn how to publish a repository on the web.
- Learn how to fetch and track a repository from the web.
In this episode, we will publish our guacamole recipe on the web. Don’t worry, you will be able to remove it afterwards.
From our laptops to the web
We have seen that creating Git repositories and moving them around is simple and that is great.
So far everything was local and all snapshots are saved under
.git.
If we remove .git, we remove all Git history of a
project.
But… - What if the hard disk fails? - What if somebody steals my laptop? - How can we collaborate with others across the web?
Remotes
To store your git data on another computer, you use remotes. A remote is like making another copy of your repository, but you can choose to only push the changes you want to the remote and pull the changes you need from the remote.
You might use remotes to: - Back up your own work. - To collaborate with other people.
There are different types of remotes: - GitHub is a popular, closed-source commercial site. - GitLab is a popular, open-core commercial site. Many universities have their own private GitLab servers set up. - Bitbucket is yet another popular commercial site.
Bitbucket
CSIRO has an enterprise bitbucket server bitbucket.csiro.au available for staff use. It offers a nice HTML user interface to browse the repositories and handles many things very nicely. Accounts use your CSIRO credentials.
Create a new repository on Bitbucket
- Login at bitbucket.csiro.au
- Click on your user profile icon, in the top-right corner, then “View Profile”
- Click “Create Repository”
On this page choose a repository name and description (screenshot).
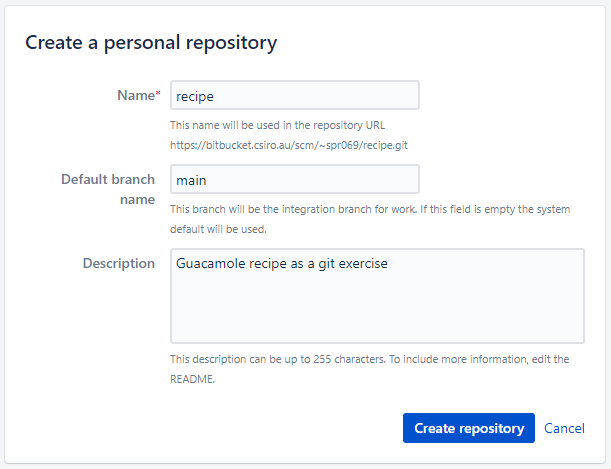
After you then click “Create repository”, you will see a page similar to:
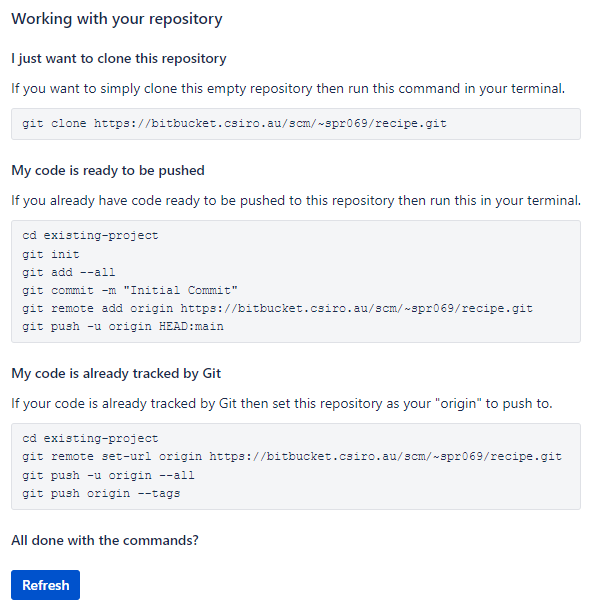
Note that this screen is telling us exactly what to do to get started
depending on different scenarios: 1. If creating the Bitbucket
repository was the very first thing we’d done, before starting work
(great forward planning!) then we could clone the
empty repository and start working in it. 2. If we’d started
working on files, but had never run git init and started
performing local git opertaions, then it tells us how to now start
tracking those files. However, it also then tells us how to link to this
online repository, adding it’s url as the “remote origin”, through
git remote add. This is where we are. 3.
The final scenario would be less used. It’s only for when a repository
had already been linked to a remote but now you’d like change it to
point this new one instead.
Creating the repository on Bitbucket effectively did the equivalent to this on the Bitbucket servers:
Linking our local repository to Bitbucket
To be able to send our local changes to Bitbucket, we need to tell
the local repository that the one we just created on Bitbucket’s servers
exists. To do this, we add a ‘remote’. Git repositories can have any
number of remotes, although it is by far the most common to only use
one. Each git remote is given a name so that it can be referred to
easily. The default remote name is origin.
As noted above, Bitbucket has provided us the instructions for how to do this under the scenario:
My code is ready to be pushed
- Go back to your guacamole repository on your computer.
- Check that you are in the right place with
git status. - We’ll copy and paste the instructed commands from Bitbucket,
however, we’ve already run
git initand already committed files, so we can ignore the first several steps, so… - Copy and paste just the last two lines to the terminal and execute those, in my case (you need to replace the “user” part and possibly also the repository name if you gave it a different one):
BASH
$ git remote add origin https://bitbucket.csiro.au/scm/<user>/recipe.git
$ git push -u origin HEAD:mainYou should now see something similar to:
OUTPUT
Counting objects: 4, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 259.80 KiB | 0 bytes/s, done.
Total 4 (delta 0), reused 0 (delta 0)
To https://bitbucket.csiro.au/scm/user/recipe.git
* [new branch] main -> main
branch 'main' set up to track 'origin/main'.Refresh your Bitbucket project website and - taa-daa - your commits should now be online!
What just happened? Think of publishing a repository as
uploading the .git part online.
When those two lines of code were run, two commands were given. The
first was to add a reference to the Bitbucket repository, and call it
origin.
The second was to push our local changes to that remote. That command was:
git push -u origin mainThis is in the format:
git push -u <remote-name> <branch-name>If you’ve got a simple repository with only one remote and one
repository, you can simply run git push.
Challenge 1
Make a change to your project and commit the changes locally.
Push the changes to your BitBucket remote.
What information can you access about the commit you just made?
Getting changes from the remote
Of course we don’t want information to only go one way - if the
remote has changes to the project from a collaborator we need to get
those onto our local machine. To do this, we’re doing the opposite of a
push, so it’s helpfully called a pull.
Challenge 2
Make a change to your repository using the Bitbucket web interface:
1. Click on a file and then click ‘Edit’ (top right) 2. Write something
new and then click ‘Commit’ (bottom left) 3. Fill in commit message (as
if you were doing a commit -m "something") and click
‘Commit’ again
Once you’ve made a change, use git pull in your terminal
to get the changes onto your local machine.
Inspect the history with git log.
Similar to git push, if you have multiple remotes and
branches, you need to specify which you are referring to by using the
format git pull <origin-name> <branch-name>,
but for our purposes git pull is sufficient.
Key Points
- A repository can have one or multiple remotes
- A remote serves as a full backup of your work.
-
git pushsends local changes to the remote -
git pullgets remote changes onto your local machine. - A remote allows other people to collaborate with you
Content from Collaborating with git repositories
Last updated on 2024-07-31 | Edit this page
Overview
Questions
- How can I contribute to a shared repository?
- How can I contribute to a public repository without write access?
Objectives
- Understand how to share a repository collaboratively.
- Learn how to contribute a pull request.
Collaborating with git remotes
One of the major advantages of version control systems is the ability to collaborate, without having to email each other files, or bother about sharedrives. We’ll consider two scenarios for collaboration:
- A remote repository where collaborators each have write acess
- A remote repository where you do not have write access
A remote with write access
Remember that a git remote is simply a copy of the .git
directory. It contains the instructions for how to recreate any state in
the history that has been captured. If more than one person is
contributing to a collaborative remote, there will be a shared history.
That is, the copy on the remote will be a combination of the history
between the collaborators.
Discussion
What do you think will happen if two collaborators make their own
sequence of commits on main and try to push them to the
same remote?
To make sure that you don’t end up with a mess of conflicting commits, it’s essential to have an agreed strategy for how to manage your contributions.
There are different models that can work, and depending on the complexity of each situation might be appropriate.
There’s a good discussion of different models, including git-flow here.
To be absolutely sure your local work won’t conflict with someone
else’s, always work on your own branch. Don’t commit directly to
main, but only merge your branch onto main
after discussion with your collaborators, or through a pull request
(discussed below).
A remote without write access
Lots of open source projects welcome contributions from the community, but clearly don’t want to give write access to just anyone. Instead, a very commonly used approach is to accept pull requests from forked versions of the repository.
Forking a repo
Forking a repository is making your own copy of a remote. For
example, a Data School example repo is hosted at
bitbucket.csiro.au/scm/dat/programmatic-data-example. By
forking that repository, you can have your own copy, retaining the
complete history of the project, at
bitbucket.csiro.au/scm/<your_username>/programmatic-data-example.
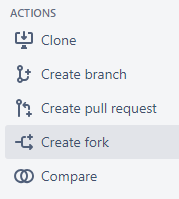
To fork a repository on Bitbucket, click on the Create Fork button in the lefthand menu of a repository’s page.
Submitting a pull request
To contribute a change to a repository that you don’t have write access to, you first of all need to make your own copy (fork the repo) which you do have write access to. You can then make your changes to the repo, and push them to your own fork.
To get them into the original repo (if that’s what you want), you need to ask the maintainers of that repository to accept them, through a pull request. You are requesting that the repository “pull” in your changes.
Pull requests as a collaborative framework
Pull requests can also be useful on a repository that you do
have write permissions on, as a collaborative, organisational, and
record-keeping tool. A common working pattern, when using Git in a team,
is to complete a body of work on a separate branch and then, rather than
doing a git merge, instead create a pull request. In doing
so, you can: * Invite collaborators to review your changes * Create
discussion around the changes (with discussions saved for posterity) *
Continue to make further edits to your changes before finally merging *
Save a formalised record of these steps having taken place
An open pull request may continue to receive further commits, by pushing changes to the same branch. This allows a pull request to act as a draft step, under review, until finally approved to ‘merge’.
Pull requests on Bitbucket
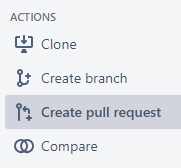
The option to create a Pull request on Bitbucket may be found in the lefthand menu of a repository’s page.
You’ll then be asked to select a source branch (the branch with new
work) and a target or destination branch (the branch to
merge into).
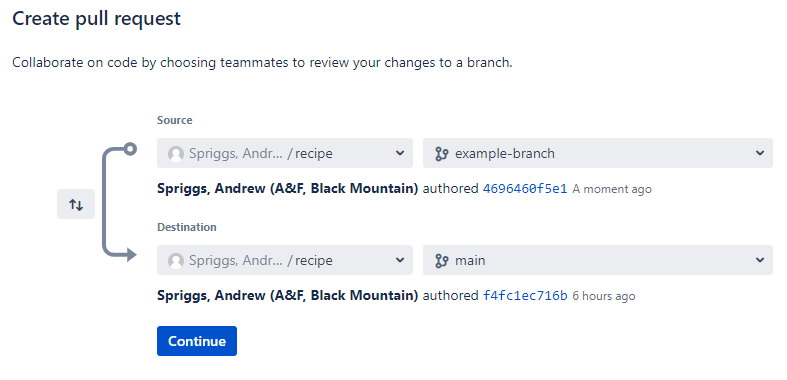
Next you’ll be able to write a description of what the pull request is about, and request specific teammates as “reviewers” of the request, before confirming the pull request.
With the pull request open, options include looking at the commits and file changes involved, writing discussion comments, starting an official review, making edits, etc.. The final goal would usually be the ‘Merge’ button, to the top-right, however other outcomes may be to decline or delete the pull request.
Challenge
Form teams of 2-3 people. One person will start.
Person 1: 1. One person from each team should create a new Bitbucket
repository named ‘favourite-things’. 2. Copy the supplied
git clone command to create a local copy. 3. Locally,
create a file named README.md and list a few of your
favourite things within it. 4. Use git add,
git commit and git push to move your new file
back to the remote. 5. In the Bitbucket repository, click ‘Repository
Settings’ in the lefthand menu, followed by ‘Repository permissions’.
Use the form to give “User access” with “Write” permissions to your team
member(s). 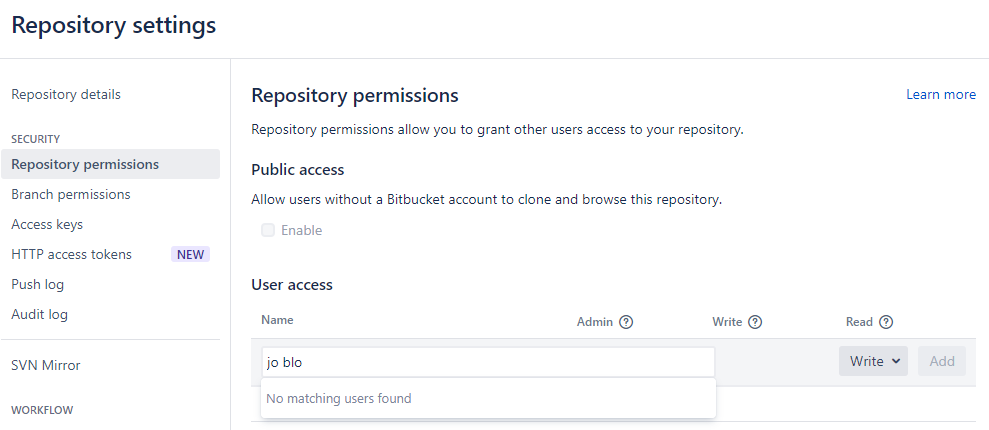
6. Share the repository link to your team member(s).
After the above, other team member(s) then: 1. Use
git clone to create a local copy of the ‘favourite-things’
repository. 2. Create and switch to a new branch (with a
meaningful name). 3. Edit the README.md file to add a few
of your own favourite things to it. 4. Use git add,
git commit and git push to get your changes to
the remote (still on your new branch). 5. On Bitbucket create a Pull
Request that would merge your new branch into the original.
Finally, together, explore the created Pull Request(s) on Bitbucket and finally “merge” them.
Bonus discussion: Why was the suggested filename ‘README.md’ specifically?
Key Points
- Sharing a repository needs good communication.
- Branches are really necessary.
- Pull requests enable sensible merging of changes between branches and across repositories.
Content from Making git citable
Last updated on 2024-07-31 | Edit this page
Overview
Questions
- How can we make a particular git commit citable?
- How can version control help reproduceable science?
Objectives
- Learn how to tag a particular git commit
- Consider for version control contributes to open science
Citing code
One of the major benefits of using code for data analysis is reproducibility and enabling transparency about the way data was manipulated and analysed. Using a version control system like git takes that to another level by enabling the sharing of the history of the code, as well allowing collaboration on code.
But because by its very nature the code may change over time, it’s necessary to be able to point to a particular point of history when we want to cite the code, such as in a research paper.
Discussion
The old way of sharing a particular version of code was to upload a
text file as supplementary material.
- What are some of the shortcomings of this approach?
- With your new expertise with git, what would be a better way?
Referring to particular commits
To enable us to accurately refer to a particular commit, we need a label for it. The hash strings that git generates could work, but they are unwieldy. Branch pointers don’t work because they stay at the tip of each branch.
Instead, git provides tags.
Tags are pointers that refer to a specific commit, and then never move.
You can give a tag any label you’d like (short, meaningful, no spaces). A classic example of a tag may be “v1.0” to denote a finalised “version 1” release of something.
Challenge
- In the vizualise git environment have a go at creating tags.
- Use
git tag [tagname] - Create a tag, then add some commits. What happens to the different pointers?
- Make some more tags, then practice doing
git checkout [tag]
Making tags static with GitHub and Zenodo
While tags are really useful to point to a particular commit, they don’t give a single access point - for example they exist in all copies of the repository, and there doesn’t have to be a publicly accessible copy. For a citation, that’s not much good. If working in GitHub, there is an option to publish a Digital Object Identifier (DOI), permanently linking to a particular tag, via Zenodo - https://docs.github.com/en/repositories/archiving-a-github-repository/referencing-and-citing-content
Open Science
Free sharing of information might be the ideal in science, but the reality is often more complicated. Often practice today looks something like this:
- A scientist collects some data and stores it on a machine that is
occasionally backed up by their department.
- They then write or modify a few small programs (which also reside on
the machine) to analyze that data.
- Once they have some results, they write them up and submit a paper.
The scientist might include their data – a growing number of journals
require this – but they probably don’t include the code.
- Time passes.
- The journal sends the scientist reviews written anonymously by a
handful of other people in their field.
The scientist revises the paper to satisfy the reviewers, during which time they might also modify the scripts they wrote earlier, and resubmits.
- More time passes.
- The paper is eventually published. It might include a link to an online copy of the data, but the paper itself will be behind a paywall: only people who have personal or institutional access will be able to read it.
For a growing number of scientists, though, the process looks like this:
- The data that the scientist collects is stored in an open access
repository like CSIRO’s Data Access
Portal, possibly as soon as it’s collected, and given its own
Digital Object Identifier (DOI). - The scientist creates a new repository on BitBucket to hold their
work.
- During analysis, they push changes to their scripts (and possibly
some output files) to that repository. The scientist also uses the
repository for their paper; that repository is then the hub for
collaboration with colleagues.
- When they are happy with the state of the paper, the scientist posts
a version to arXiv or some other
preprint server to invite feedback from peers.
- Based on that feedback, they may post several revisions before
finally submitting the paper to a journal.
- The published paper includes links to the preprint and to the code and data repositories, which makes it much easier for other scientists to use their work as starting point for their own research.
This open model accelerates discovery: the more open work is, the more widely it is cited and re-used. However, people who want to work this way need to make some decisions about what exactly “open” means and how to do it. You can find more on the different aspects of Open Science in this book.
This is one of the (many) reasons we teach version control. When used diligently, it answers the “how” question by acting as a shareable electronic lab notebook for computational work:
- The conceptual stages of your work are documented, including who did
what and when. Every step is stamped with an identifier (the commit ID)
that is for most intents and purposes unique.
- You can tie documentation of rationale, ideas, and other
intellectual work directly to the changes that spring from them.
- You can refer to what you used in your research to obtain your
computational results in a way that is unique and recoverable.
- With a version control system such as Git, the entire history of the repository is easy to archive for perpetuity.
With tools like R Markdown and Jupyter Notebooks, documentation may be mixed directly with code to generate graphs and images for the same documentation, and all stored in version control!
Licenses and citations
A final note to keep in mind if sharing a Git repository publicly- it may be important to include some licensing information (often done in a LICENSE.md file) instructing under what conditions others are welcome to use/modify your work. Example IM&T may help with this if necessary.
Similarly, a citation file may be useful to include, with a request for how you’d like your work to be cited. A special format is proposed specifically for this purpose, in the form of a CITATION.cff file, containing a standardised set of information that is both human and machine readable. E.g.:
cff-version: 1.2.0
message: "If you use this software, please cite it as below."
authors:
- family-names: Druskat
given-names: Stephan
orcid: https://orcid.org/1234-5678-9101-1121
title: "My Research Software"
version: 2.0.4
doi: 10.5281/zenodo.1234
date-released: 2021-08-11More information is available here: citation-file-format.github.io
Key Points
- Git tags may be generated to note a particular version in history.
- Consider use of git early in scientific workflows, for robust documentation.
- Open scientific work is more useful and more highly cited than closed.
Content from What to not add to Git
Last updated on 2024-07-31 | Edit this page
Overview
Questions
- What should be included in Git repositories?
Objectives
- Consider the dos and don’ts of Git usage
What to not add to Git
A final note on what should and shouldn’t be included in Git repositories.
In general, Git can describe individual line changes for any sort of
file that may be opened within a text editor. This includes many forms
of code, documentation, HTML, simple data files, etc., but excludes
other binary formats like: - Microsoft Office documents and other rich
text documents
- PDF files
- JPEG/PNG images
- Zip files
- Proprietary data files
- Etc..
Git may still store these files, but any version history would be less meaningful, without clear ‘diffs’.
More importantly though, Git repositories should not be used to
store: - Personal information, especially usernames, passwords, keys,
secrets
- Details that are specific to an individual computer or system
(e.g. use relative paths rather than full system paths)
- Large volumes of data / input files (make use of services like the DAP for these)
- Compiled executables, software libraries, and other files that may be
regenerated by scripts when needed
Remember to make use of .gitignore files to ignore and exclude files
as necessary.
Key Points
- Make use of .gitignore to list files to exclude.
- Don’t commit sensitive, personal or machine-specific information.
- Don’t commit large data files.
- Git works best with text files, for which it can track individual line changes.